
Компьютеры находят все более широкое применение во всех областях человеческой деятельности. В настоящее время сдерживающим фактором к увеличению количества компьютеров в мире является неприятие их неподготовленным пользователем, его страх перед компьютерами. В определенной степени это неприятие связано с традиционными для вычислительной техники способами ввода информации, в первую очередь, ввода с клавиатуры.
В настоящее время во всем мире ведутся работы по созданию более естественных для человека средств общения с компьютером, среди которых первое место занимает речевой ввод информации в компьютер. Проблема речевого ввода информации осложняется рядом факторов: различием языков, спецификой произношения, шумами, акцентами, ударениями и т.п. Данная работа посвящена разработке приемов и алгоритмов распознавания речи на русском языке.
В любом языке существует некий набор звуков, который участвует при формировании звукового облика слов. Как правило, звук вне речи не имеет значения, он приобретает его лишь как составная часть слова, помогая отличить одно слово от другого. Элементы этого набора звуков называются фонемами.
Процесс произнесения звуков речи имеет несколько основных стадий.
Легкими создается поток воздуха, который проходя через гортань, ротовую и носовую полость получает полезную информацию, которая распространяется в пространстве в виде звуковых волн. Звуки могут формироваться при участии истинных голосовых связок и без их участия и от этого коренным образом меняется их образ. Звуковые колебания воспринимаются микрофоном, и как результат преобразования имеется аналоговый сигнал, что дает возможность применить аналоговые методы анализа сигнала. Как правило, на этой стадии могут применяться системы фильтров. Однако, если рассматривать распознавание речи в приложении к компьютерным технологиям на уровне программного обеспечения, то необходимо провести следующий этап преобразования информационного образа речи - из аналогового сигнала в непрерывно-дискретный.
Преобразование реализуемо с применением различных видов аналого-цифровых преобразователей. Главным требованием к ним является достаточность качественных характеристик преобразования. Такими качественными характеристиками являются частота дискретизации и разрядность представления каждой дискреты.
Частота дискретизации определяет ту предельную частоту аналогового сигнала, которая может быть информативна в дискретном представлении. Из исследований в технической фонетике, в частности, в телефонии известно, что приемлемый диапазон частот, при котором человек может распознавать речь и определить говорящего является 4. Именно это значение легло в основу частотного уплотнения каналов в телефонии и определении пропускной способности цифровых каналов связи.
Анализ аналоговых характеристик речи показывает, что реально частота дискретизации должна быть не менее 8 - 12 Khz. При дальнейшем понижении частоты начинает теряться информация, которая активно используется при распознавании (особенно это важно при распознавании звуков, содержащих шум). Нет смысла поднимать частоту дискретизации выше 25 Khz, так как при незначительном увеличении полезной информации, начинает увеличиваться количество бесполезной информации - шумов.
По диапазону количества разрядов, передающих дискретный сигнал, достаточно 8 разрядов, но при условии хорошего качества сигналов и его высокого уровня. Человек способен воспринимать речь в более худших условиях, чем описанные выше, например, телефонные разговоры. Однако, при восприятии речи человек использует механизмы ассоциативного анализа, не просто разбирая и сравнивая услышанные звуки, но собирая фонемы в словесные образы, подбирая наиболее подходящие не только по звуковому подобию, но и по интонации, эмоциональной окраске, контексту слова, фразы, предложения и всего текста. Поэтому, человек способен распознавать речь даже при большой нехватке несущей информации. Например: человек намного требовательней к качеству звука при прослушивании речи на чужом языке, при слабом его знании, чем при восприятии родной речи.
Обратимся к полученной после дискретизации осциллограмме речи. В общем случае информация в виде образа речи может быть представлена последовательностью участков. На одних прослеживаются некие периодические процессы различной амплитуды (см. рисунок), другие представляют из себя различные виды шумов, третьи - участки с сигналом, близким к нулевому значению, четвертые могут быть описаны как скачки.
Над полученным образом речи можно производить работу по распознаванию. Рассмотрим иерархию построения системы распознавания речи. В качестве простого примера рассмотрим схему распознавания, когда сигнал делится на два слова (для уверенного деления в простейших случаях достаточно полуторносекундной задержки между словами при произношении). Слова, в свою очередь, распознаются как единое целое. При этом используются различные методы сравнения с эталонами, вид которых зависит от методики распознавания: при использовании методов динамического программирования эталоны представляются в том же виде, что и поступающий сигнал (с учетом деления на слова), при применении методов разложения в ряды, эталоны представляют из себя наборы параметров этого ряда.
Результатом работы этой схемы является слово из списка присутствующих в множестве эталонов или сообщение об ошибке, если полученный образ не соответствует в достаточной мере ни одному эталону.
К недостаткам такой системы можно отнести: необходимость создания совокупности эталонов фактически для каждого человека (так называемый процесс обучения системы распознавания), невозможность создания автоматической системы коррекции эталонов, пропорциональность времени, затрачиваемого на распознание слова, количеству эталонов, и необходимость конечного выбора из нескольких возможных вариантов.
Из-за перечисленных недостатков описанная схема может применяться только при необходимости распознавания ограниченного списка слов одного или нескольких операторов. Например, в различных системах управления с небольшим количеством команд.
Улучшить качество работы рассмотренной выше одноуровневой системы распознавания возможно за счет увеличения количества уровней. Пусть рассмотренная нами система распознавания слова из совокупностей шаблонов занимает средний уровень нашей иерархии.
Добавим к распознаванию среднего уровня еще один, верхний, уровень. На этом уровне предполагаемое слово анализируется с точки зрения фразы в целом. В результате, за счет синтаксических и семантических свойств языка приобретается дополнительная информация, повышающая качество распознавания.
Однако, идея увеличения количества информации о слове необязательно должна быть связана с верхним уровнем. Рассмотрим более нижний уровень иерархии, где производится фонемный разбор речевого образа, то есть деления выделенных слов на фонемы с последующим их распознаванием. Это позволило производительно использовать распознавание по иерархической схеме: из списка фонем, распознанных с определенной точностью, составляется шаблон, который передается на следующий уровень, где по нему происходит подбор наиболее подходящего слова, передача информации о выборе на более высокий уровень, для дальнейшего анализа, и на нижний, для подстройки системы на конкретного пользователя. Достоинством это схемы является высокая адаптивность, дающая возможность динамической самоподстройки системы на оператора, и многоуровневая система проверок, повышающая точность работы.
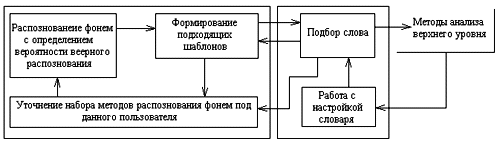
Сравнивая распознавание речевого потока методом распознавания целых слов и распознавание фонем, можно сделать вывод: при небольшом количестве слов, используемых оператором, более высокую надежность и скорость можно ожидать от распознавания целых слов, Но при увеличении словаря скорость резко падает. Предположительно, размер словаря системы распознавания уже в сотню слов делает переход на уровень более низкий, чем распознавание слов в целом актуальным.
Звуки, участвующие в формировании речи, имеют две основные классификации: по артикуляционным признакам и по акустическим признакам.
Классификация звуков по артикуляционным признакам является крайне важной при использовании методов генерации и распознавания речи с помощью моделирования носоглотки, но для решения задач деления на фонемы более интересно рассмотрение акустических различий звуков. По акустическим признакам звуки подразделяются:
Тональные звуки - образуются голосом при полном отсутствии шумов, что обеспечивает хорошую слышимость звука:
гласные: а, э, и, о, у, ы.
Сонарные (звучные) - чье качество определяется характером звучания голоса, который играет главную роль в их образовании, а шум участвует в минимальной степени:
согласные: м, м’, н, н’, л, л’, р, р’, j.
Шумные - их качество определяется характером шума - акустического эффекта от трения воздуха при сближенных или взрыве при сомкнутых органах речи:
- звонкие шумные длительные: в, в’, з, з’, ж;
- звонкие шумные мгновенные: б, б’, д, д’, г, г’;
- глухие шумные длительные: ф, ф’, с, с’, ш, х, х’;
- глухие шумные мгновенные: п, п’, т, т’, к, к’.
По производимыми звуками акустическому впечатлению выделяют следующие группы звуков:
- свистящие: с, с’, з, з’, ц;
- шипящие: ш, ж, ч, щ;
- твердые: п, в, ш, ж, ц и др.;
- мягкие: п’, в’, ч, щ и др.
Для дальнейшего анализа проведем информационные образы звуков различных групп (см. рисунки).
Разница образов и звуков различных видов велика, что значительно облегчила бы задачу разделения звуков, если бы не присутствие нескольких затрудняющих работу факторов.
Во-первых, переход между различными звуками, как правило, осуществляется крайне плавно даже между звуками различных групп (исключение составляют некоторые взрывные согласные). Если же говорить о звуках одной группы, то становится проблематичным разделять переходные процессы от произнесения того или иного звука, например, в последовательности, воспринимаемой человеком как “иау”, звук “а” фактически полностью теряет свой обычный образ в переходе от “и” к “у”. Под влиянием “и” и “у” несколько уменьшилась частота в “а”, да и сама форма звука несколько трансформировалась.

Во-вторых, затруднительно назвать какие-либо постоянные критерии для успешного деления на звуки в связи со сложностью процесса их образования.
Вернемся к отображениям звуков и проанализируем общий вид гласных и сонарных звуков. Легко выявить некую общую закономерность, которая обусловлена происхождением звуков - звуки этих видов отдаленно напоминают реакцию некоторой системы на последовательность равноудаленных импульсов. Действительно, импульсами гласных и сонарных звуков являются колебания истинных и звуковых связок. Окончательный вид звуковые волны приобретают после прохождения через носоглотку, которая по своей сути является системой фильтров. Необходимо отметить, что изменения в напряжении истинных голосовых связок и артикуляции происходят значительно медленнее, чем колебания голосовых связок.
Заметим, что гласные и сонарные звуки состоят из участков затухания импульсов от основных (необертонных) колебаний истинных голосовых связок. Для упрощения, будем называть эти участки доменами.
Использование домен при распознавании речи вполне очевидно. По сути, домен (вспомним, что пока домен рассматривается в приложении только к сонарным и гласным звукам) содержит в себе информацию, достаточную для распознавания звука. Если взглянуть на образ протяженно произнесенной гласной (или сонарного звука), то за исключением небольших по длине участков в начале и конце образа звук состоит из домен с высокой степенью идентичности, даже для различных людей многие характеристики, а соответственно, и общий вид домен во многом схожи, что придает особую универсальность методам распознавания при выделении и распознавании фонем через домены. Еще одним достоинством домен является относительная простота их выделения. По определению, домен начинается с максимального значения в определенном диапазоне, после которого идет затухающий по некоторому закону колебательный процесс. Как дополнительное условие, которое можно использовать при расчленении речи на домены, можно перечислить:
стабильную (в диапазоне) длину домен;
постоянную, с некоторой точностью, величину максимумов, по которой происходило вычленение домен.
Доопределим понятие домена для остальных групп звуков.
Структура звонких шумных длительных звуков крайне сходно со структурой сонарных и гласных. Основным различием является наличие шума. Появление шума строго закономерно для каждого отдельно взятого звонкого шумного длительного звука, так что принцип деления на домены остается прежним.
Будем рассматривать шумные длительные звуки как один домен. Это позволит легко выделять корень этих звуков из общего потока и облегчит их анализ.
Анализ образов шумных мгновенных (взрывных) звуков показывает наличие участков по структуре схожих с определенным для гласных и сонарных звуков понятием домена. Но наряду с совокупностью общих признаков прослеживается различие: для вышесказанных участков в шумных мгновенных звуках отсутствует та строгая идентичность домен между собой. Во всех мгновенных звуках присутствует момент, сильно облегчающих их выделение из речи - перед произнесением таких звуков наблюдается непродолжительная по меркам восприятия, но весьма значительная, в масштабах длительностей домен, пауза. Это помогает выделению домен. Поэтому в зависимости от различных алгоритмов выделения может быть удобно разбивать такого рода звуки на несколько домен или же воспринимать их целиком, как один.
При разбиении потока речи на домены мы получаем еще один уровень в распознавании. В общей иерархии он находится еще ниже, чем уровень распознавания домен. Рассмотрим функционирование такой системы.
Процесс распознавания начинается с поступления системы данных об образе речи. В зависимости от того как поступает информация в систему, непрерывно поступающий поток или же уже отдельные пакеты (например, слова), построен алгоритм деления. Если в распоряжении данного уровня распознавания имеется слово целиком, то работу можно описать следующим образом.
Сначала производится предварительный анализ полученного блока данных, результатом которого должно являться выделение участков шумов для распознавания глухих шумных длительных звуков и выделения домена взрывных звуков. Выделенные участки помечаются. Далее производится поиск максимумов среди нулей первых производных. Определяется список экстремумов в диапазонах. Далее проводятся проверки на плавное изменение длительности домен и значение экстремумов, что служит критерием отбора домен.
Полученный список уже готов для передачи на уровень распознавания фонем по информационному потоку, деленному на домены, однако возможно и желательно введение дополнительных проверок и формирование вспомогательной информации для упрощения распознавания фонем. На уровне распознавания фонем происходит конкретизация взрывных и глухих шумных длительных звуков. Далее производится работа по селекции переходных домен и домен, по которым будет производиться основная работа по распознаванию фонем.
Обобщенно говоря, уровень деления на домены было бы точнее назвать некоторым подуровнем в распознавании фонем, так как здесь не происходит преобразование вида информационного. Однако, по своей сути процесс выделения домен сложен и многопланен, поэтому он может рассматриваться отдельно, со своими внутренними подсистемами и совокупностью данных.
Некоторые части рассмотренных алгоритмов и способов распознавания удобнее реализовать на аппаратном уровне. Вполне достаточно системы на основе процессора 486 DX4-100/8Мб ОЗУ. При использовании аппаратных средств реализации , например, процессора ASP, входящего в комплект поставки некоторых плат, требования к основному процессору могут быть существенно уменьшены. По нашему мнению использование домен позволит создавать универсальные системы распознавания речи, работающие в фоновом режиме.