Today we collide very frequently with an abbreviation «MP3». Computer users, music fans and many others may meet this denotation on a shop shelf, in magazine, in Internet and on various logotypes. Although once it was only a little-known innovation, MP3 has already “knocked on many doors”, either through the Internet or as electronic audio products. Today MP3 is, perhaps, the most widespread, disposable and known format for storage of music in digital representation. Due to more and more spreading embedding of MP3 in electronic devices and home appliances, this outstanding technology becomes even more used and widespread.
MP3 has received its wide popularity quite deservedly; however this fact has played also a negative role: many skeptically adjusted users perceive wide popularity as low quality. It is sad to point out, but frequently, even quite experienced computer users, perceive this sound storage method as, admittedly, a low-standard and refer to it frivolously. MP3 has earned such undeserved attitude in the Internet. Internet already for a long time teems with audio files in this format; however most of them have very poor quality. The principal cause of such situation consists not in low sound quality which MP3 provides, but in incompetence and amateurishness of those users who share in the Internet ineptly compressed low-quality audio materials.
This article is not just about MP3. Here we will try to clear up how to use correctly today’s audio compression technologies, similar to MP3; we will mention the questions concerned with modern audio encoding methods, with their advantages and deficiencies; we will clarify, how it is possible to receive a qualitative sound using MP3, OGG, AAC, MPC, WMA and other formats, and we will discuss also other accompanying questions concerning audio compression.
Let’s stipulate at the beginning, that MP3 is not panacea. There are many other similar technologies (techniques) of audio encoding and on many of them we will elaborate in more details. We started this article with the discussion of MP3 because it is well known abbreviation and almost every user sees it everyday.
I. Analog and digital representation of sound signals
To make easier understanding of the further material, we will show at the beginning some well-known fundamental concepts from physics of a sound.
What is the sound and how we hear it? An acoustic wave is mechanical oscillations of air molecules, which are transmitting in space. Sound, audible signal is a set of acoustic waves. Oscillations of air, getting into human auricle, pass through the complex system of the hearing aid and stimulate nerve-endings. A brain, analyzing the received information, «hears» sound with various altitude, direction and power. Force of felt sound vibrations depends on their amplitude. In classical definition, amplitude is the greatest (maximum) deviation of a sine-wave acoustic wave (varying in time and space, strictly according to the sine-wave law) from a zero value. Discussing real audible signals (complex non-periodic oscillations), by signal amplitude in practice we denote current magnitude of a signal at present time point.
In audio equipment, sound is represented by continuous electrical signal or by set of digits (zeros and ones). Equipment which operates with continuous electrical signal is named analog equipment (for example, radio receiver, oscilloscope, etc.). Signal transmitting through such equipment is called analog signal. Conversion of acoustic wave into analog signal can be carried out, for example, by the following method. Diaphragm of a thin metal with the inductor spooled on it, being in electrical circuit and affected by a constant magnet, submits to oscillations of air and produces corresponding voltage oscillations in current circuit. These current oscillations in current circuit simulate original acoustic wave. Principally, this method is used in microphone to convert sound vibrations into analog signal. Analog signal can be stored on magnetic tape and can be subsequently played back.
As is well known from physics, audio signal can be represented as a spectrum of frequencies (a frequency spectrum). Frequency components of the spectrum are sine wave oscillations (so-called pure tone), when each of these oscillations has its own amplitude and frequency. Generally, any, even very complex oscillation (for example, human voice or music), can be represented by sum of elementary sine wave oscillations with certain frequencies and amplitudes. And on the contrary, having generated various sine wave oscillations (with different frequencies and amplitudes) and having summed them (having mixed them together) it is possible to combine various audio signals. For instance, let’s consider an acoustic wave derived by superposition of three sinusoids with frequencies of 500 Hz, 2000 Hz and 2500 Hz (see figure 1).
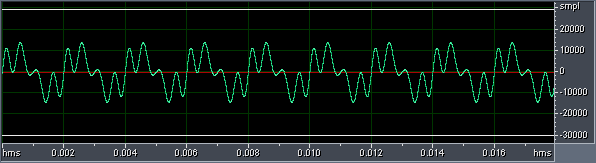
fig. 1
And now let’s look at the frequency spectrum of such acoustic wave (see figure 2).
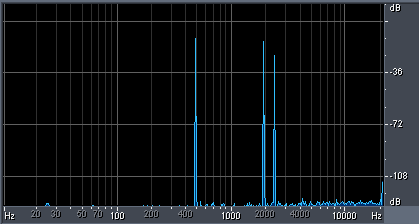
fig. 2
As we can see on the figure 2, signal spectrum contains peaks on the frequencies corresponding to sinusoids and complete «silence» in other points of a spectrum. The altitude of each pica shows amplitude of the corresponding sinusoid.
Footnote:
* The human hearing aid is capable to recognize sound frequency components in the range from 20 Hz up to ~20 kHz (the upper bound can vary, depending on age of listener and other factors).
* Generally speaking, our discussion about classical decomposition of a signal in a frequency spectrum is fair only concerning periodic signals. The frequency analysis of real, acyclic signals is performed by blocks: the signal is being divided and analyzed by, when each signal block is considered as one period of periodic signal.
Now let’s talk about concepts which are closer to a digital sound. It is well known that a computer operates with the data in a digital form. Therefore, for further discussion, it is necessary to clarify how it is possible to represent audio signal in a digital form.
Digital sound is the analog audio signal represented by discrete numerical values of its amplitude. Real audio signal is a complex oscillation, certain complex dependence of amplitude of acoustic wave on time. A method of conversion of analog audio sound into digital form (analog-digital conversion) consists in metering of signal amplitude with certain time step and subsequent storing of the obtained amplitude values as numbers. There are some complexities in this, apparently, a simple method. Namely, values of signal amplitude cannot be written with infinite accuracy and consequently they are necessary for rounding off. Thus, during analog-digital conversion we approximate an analog sound wave at once on both two coordinate axis’s – time and amplitude axis’s, that is, we take values of amplitude of a wave with the defined time-step and write them with finite accuracy.
Speaking in more formal language, analog-digital conversion of signal includes two processes – discretization in time (sampling) and quantization of amplitude. The process of a time sampling is a process of obtaining of signal values with the certain time step – sampling step (see fig. 3). For simplicity sake we’ll consider, that the sampling step is constant, however this condition is not necessary.
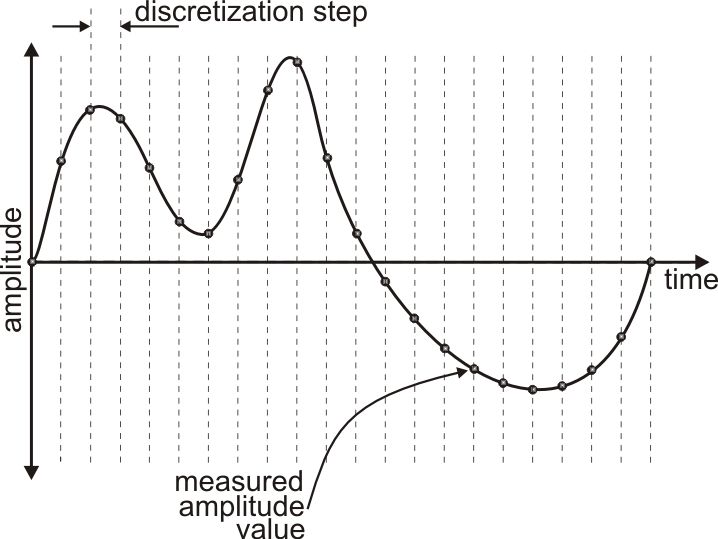
fig. 3
The less time step is, the more often we obtain amplitude values. Number of amplitude metering per second is called sampling rate. Amplitude quantization is a process of replacement of real signal values by rounded ones with the defined accuracy (see fig. 4).
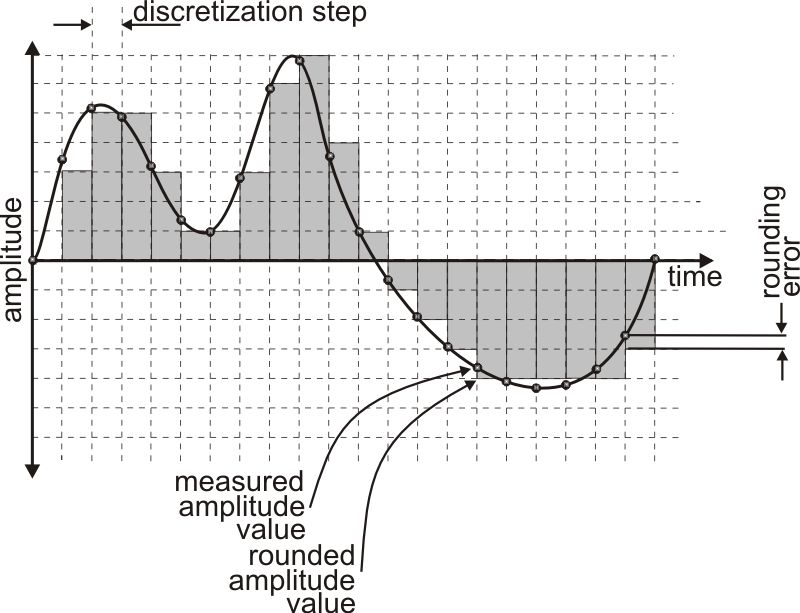
fig. 4
Rounding accuracy depends on chosen number and position of quantization levels: the more levels of quantization and the closer they are, the less each measured amplitude value needs to be rounded, and, thus, the less obtained error. So, analog-digital conversion of a signal is a registration of its amplitude values with defined time step and their storing as rounded digital values . Stored numerical values of signal amplitude are named samples . It is obvious, that the more often we meter signal amplitude (the higher sampling rate) and the less we need to round obtained values (the higher quantization resolution), the more precise digital representation of the signal we obtain. It is necessary to notice here, that when we talk about more or less exact representation of signal, we mean worse or better distortion and noise pollution of sound. For example, digital signal which was obtained by realizing analog-digital conversion on low sampling rate will sound noisy. The same statement refers also to quantization resolution.
Footnote:
Hereinafter we will repeatedly use the notion “sounding quality". It is important to notice, that this notion is absolutely biased and has nothing in common with any evaluative physical characteristic of sounding. It is due to the fact that each listener has its own individual perception. “Sounding quality” characterizes, more likely, a degree of listener’s satisfaction by the sounding. Sounding quality is defined by presence and "behavior" of high frequencies (in frequency band of 5 kHz and higher) whereas lower frequencies define sounding clearness. For example, human speech and music cannot be understood without presence of the low frequencies whereas the high frequencies make the sounding more clear and qualitative.
Obtained after analog-digital conversion, digital data (set of consecutive values of amplitude) can be stored in computer memory. This data format is called PCM (Pulse Code Modulation).
It is necessary to say some words about human perception of sounding spatiality. Human hears by two ears and due to this he is capable to distinguish a direction of arrival of sound signals. There is a simple explanation of this. Human ears are placed on a certain distance on both sides of the head. Sound wave distribution speed is relatively insignificant. Sound signal, which comes from the source located in front of the listener, comes to both ears simultaneously and the brain interprets this as it were signal source, located either behind or in front of the listener, but not sideways. If the signal comes from a source displaced relatively to the center of listeners head, then sound comes in one ear faster than in the second one and this in an appropriate way allows the brain to recognize arrival of a signal from the left or the right. If we accomplish sound recording with the help of one microphone only, then when playing back of recorded signal through one or even number of loud-speakers, the listener won’t be able to feel a spatial picture of original sounding, since the recorded signal is a monophonic (or single-channel) record (recorded only from one point of space). If recording has been made with the help of two microphones simultaneously, located in two different points of space, (actually, two independent parallel records), then playing back of such signal through two loud-speakers (correctly located relatively to the listener) will enable the listener to feel almost full spatiality of sounding of an original signal. Such record (i.e. two parallel records of the same signal made in different points of space) is called stereophonic or two-channel record (see fig. 5).
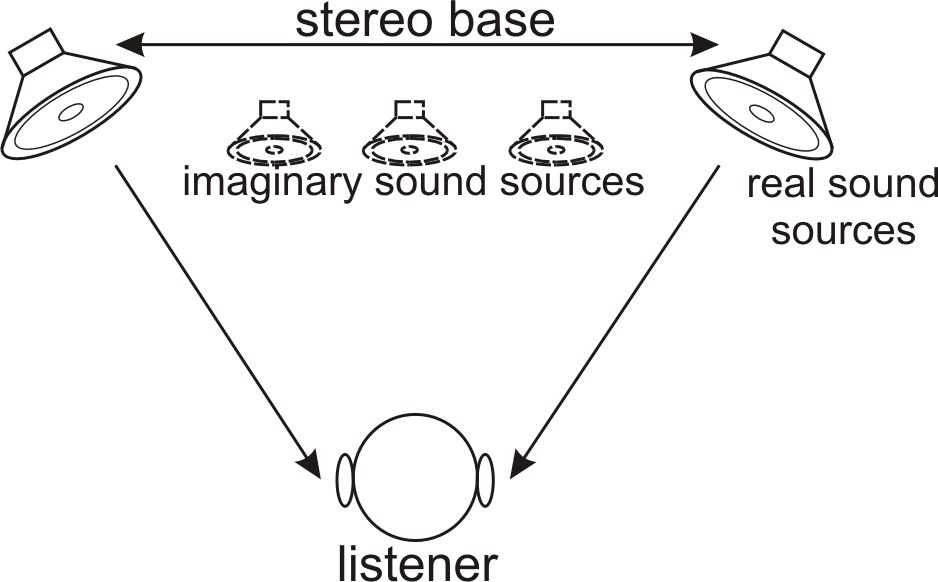
fig. 5
Reproduction quality of original sound spatiality can be raised by supplement of additional channels when recording (that is, accomplishing of signal record from three and more points of space).
II. Audio coding methods
As we see, by simple analog-digital conversion of analog sound material with high sample rate and quantization resolution, it is possible to store audio material in computer memory without almost any loss of quality. Then a question is raised: what for is this great amount of various audio compression technologies (like MP3 and other)?
There are various reasons for that. As a matter of fact, the wish to keep original quality of audio materials after its conversion from analog into digital form, encounters definite difficulties. According to Nikewist (Kotelnikov) theorem, sample rate sets upper bound of frequencies in the signal, namely, maximum frequency of spectral components of digital signal is equal to half of its sampling rate. Bluntly speaking, to obtain full spectral image of original analog signal in frequency range 0 - 22050 Hz (the maximal range of perceptible frequencies for human) it is necessary to choose sample rate to be no less than 44.1 kHz. It means that the wish to keep original quality of audio material obliges us to choose high parameters values of analog-digital conversion. However, the higher the values are the greater amount of memory is needed to store digital data. For example, standard audio CD (650 Mb) stores audio data in format PCM 44.1 kHz / 16 bits / stereo. Such parameters correspond to two-channel record with 65536 (2 16) quantization levels of amplitude, which values are taken 44100 times per second. Making very simple calculation, we ascertain that standard audio CD contains about one hour of music. Basically, it is not such a big value, taking into account that medium audio collection may be thousands hours long. It is necessary to notice here, that standard file type for storing digital audio today is .WAV file. It is a universal container, which allows storing digital audio with different sampling rates and quantization resolutions.
So, as we see, to have an opportunity to store great amounts of audio at high quality it is necessary to resort to various tricks which help in storing of audio data occupying less memory. The tricks we’re talking about are compression (coding) methods which gain in data size at the expense of some loosing of original sound quality. About these tricks we are going to talk now.
There are two prevalent ways of coding of audio data (except for simple storage in pure digital form «as is» which was shown above).
Footnote:
* Data coding - representation of the data in a certain system of coding symbols and their structures. Enciphering, and also compression of the data are special cases of coding.
* Under data stream we mean contents of a file; data downloaded from the Internet or any other consecutive digital data.
1. Lossless data compression is a way of audio data encoding which allows total-lot data restoration from compressed form back to the original stream. Such way of data compression is used when it is necessary to store data without any loss of quality. For example, working with audio in sound studio, after data was recorded, it needs to be stored in sound archive for the following processing or publishing. Today’s lossless data compression methods (like Monkey’s Audio, Flac, WavPack, TTA, OptimFrog, etc) allow reducing data size by 20-50% along with providing hundred-per-cent restoration of the original data from compressed stream. Such coders are some kind of data archivers (as, for example, ZIP, RAR and others), but intended specially for compression of audio data.
Footnote:
* Coder is a program (or hardware device) implementing certain algorithm of data coding (for example, ZIP archiver or MP3 encoder). It transforms initial data stream in its source format into certain encoded (compressed) form (format).
* Decoder is a program (or hardware device) which implements decoding of the encoded data.
* Codec (COder/DECoder) is a program / software driver / hardware device intended for data coding / decoding.
Lossless compression is ideal in respect to source data safety, but it is unable to provide with high compression.
2. There is also another way of audio compression – compression with loss of quality (so called, lossy coding). The aim of such coding: in any way to achieve sounding similarity of compressed data with original audio material, along with maximal profit in size. This aim is reached today by using various algorithms which «simplify» an original audio signal, throwing out from it «unnecessary» almost inaudible (or indiscernible by a human ear) details. After lossy coding, decoded signal sounds similar to the original material, but actually ceases to be identical to it. There are several lossy codecs available. The most known are: MPEG-1 Layer 3 (it is the correct official name of the well known «MP3»), MPEG-2/4 AAC (MPEG-2/4 Advanced Audio Coding), Ogg Vorbis («OGG» in abbreviated form), Windows Media Audio (WMA), MusePaсk (MPC) and others. The benefit of using such audio compression methods is quite obvious: compression factor provided by such coders is on average within the limits of 7-14 (times) and these results reached at almost undistinguished losses of sounding quality. Practically it means that one regular audio CD track copied to hard-disk as a .WAV-file is about 35-55 Mb long (PCM 44.1 kHz / 16 bit / stereo), but being compressed into MPEG-1 Layer 3 (MP3) it becomes 3-7 Mb long, and all this with more than satisfying sound quality.
As we have said, compression of data in lossy-coders is accomplished by simplification of audio data. The main idea of almost all lossy encoders is based on using of so-called psycho acoustic algorithms of sound analysis (psycho acoustic model), which is used to “simplify” audio data during compression. Mechanism of coder, which is based on simplification of signal spectrum (there are also coders, which are based on other techniques) works approximately as follows. The encoder analyses the signal during compression, determining frequency spectrum areas with inaudible to a human ear nuances and moving them off. These nuances are masked or poorly heard frequencies, short-term inaudible bursts, low-level noises and so on. Such processing simplifies the form of an original sound wave, making it “smoother”. Compression factor of the original signal depends on a degree of its «simplification»; good compression is achieved by «aggressive simplification» when the coder considers as insignificant a great many nuances. I.e. the stronger simplification, the better compression is achieved. Too aggressive compression, naturally, results in strong degradation of quality, because many of audible details could be considered as insignificant and maybe deleted by the coder. Distinctive feature of all modern lossy-coders is the opportunity of fine adjustment of coding parameters. This feature, combined with competent approach and correct understanding of compression methods, allows achieving high data compression factors at completely imperceptible original quality loss.
Now let’s talk a bit deeper about the method of signal simplification (once again, on the example of encoder which is based on spectrum simplification techniques). The mechanism of audio signal simplification can be explained as follows. Initial audio data is divided on blocks of the certain length. After division, each block is processed separately. During coding, each block is decomposed into frequency spectrum. As we have said, the less nuances the signal has (i.e., the more “simple” the signal is, or in other words, the less frequency components its spectrum contains), the more effective compression can be reached. There are some possibilities to simplify the signal. For example, it is possible to filter (to exclude from the spectrum) all frequency components above some boundary. This will null the signal in high bandwidth, improving compression, but this also will have bad influence on sounding quality. However, main way of simplification is applying of psycho acoustic model: coder analyses the signal considering which spectrum components are unnecessary or inaudible, and excludes them from the spectrum.
Footnote:
* Bitrate - amount of bits used for storing of one second of audio. For a standard .WAV-file in format PCM 44.1 KHz / 16 bit / stereo the bitrate is: 44100 (amplitude values per second) * 16 (bits per one amplitude value) * 2 (channels) = 1411200 bits per second = about 1378 Kbps (Kilobit per second).
* Usually user can specify preferred bitrate (as good as other parameters) or bitrates range before compression. The lower bitrate is, the fewer bits the coder may allocate for storage of one second of audio data and, thus, the deeper simplification the signal passes during compression (that accordingly influences quality of sounding). The most prevalent average bitrate value for MP3’s downloaded from the Internet changes in the range of 128 – 192 Kbps.
It is necessary to notice especially, that using of psycho acoustics as sound simplification method during compression leads to impossibility of getting exactly the same signal as source signal on decoding. This is because of irreversible changes of original data during compression. That is why such compression method is called “lossy coding”. So, every time when you use lossy-coders you should bear in mind this aspect. For instance, if you compress music for your audio collection, you should not limit the bitrate too much, because in doing so you might mar the quality of resulting audio stream. On the other hand, with competent approach, as a compression result you may get very good compression factor (as is the purpose of coding) plus high sounding quality.
III. A compression in practice
To take advantage of opportunities of audio coders and to compress required audio data in chosen format (for example, in MP3) practically, at first it is necessary to prepare the data. It touches on the data stored on some analog storage (on magnetic tape, for example). Of course, at first you need to copy the data into computer by converting materials from analog to digital form.
As we said above, analog-digital conversion process consists in sampling and quantization. In practice, these processes remain invisible to the user: all draft work is done with various programs which give corresponding commands to sound card driver (it is managing subroutine of operation system). The only things the user needs to do is to connect playing back equipment to an input of the sound card by cables, to set all necessary analog-digital conversion parameters (sampling rate, quantization resolution and number of channels), to turn on playback mode (using any of the available sound recording programs) and to wait until recording process is finished. After recording is finished, user may store obtained data in file (for example, in PCM WAV format).
Digital data (as WAV-file) can be compressed with chosen coder (whether WMA, MP3 or another). In order to compress file (or files) user should start corresponding program (we will discuss available coders later), choose compression parameters (bitrate and others) and start the compression. On today’s computers, encoding of 50 Mb WAV-file takes only minutes. Obtained compressed files occupy much less memory/disk space, rather than initial .WAV-files. And as it has been noticed before, using right thought-out compression parameters, encoded audio material sounds as good as the original.
Encoded files can be kept in your audio collection or even taken with you inside of your portable audio player.
IV. Lossy audio codecs MP3, OGG, WMA, AAC and MPC in more detail
Here are some of modern lossy-coders that exist today: MPEG-1 Layer 3 (MP3), Windows Media Audio (WMA), Ogg Vorbis (OGG), MusePack (MPC), and MPEG-2/4 AAC. We shall elaborate in detail on consideration of these five codecs, which are most used today.
MP3 - MPEG-1 Layer 3
MPEG standards in general and MP3 in particular
MPEG-1 Layer 3 (known as «MP3») is most widespread and popular today. It has won its popularity quite deservedly – it is the first widespread lossy-codec which reached such a high data compression factor, together with very good sounding quality. A little bit of history. MPEG is an abbreviation of «Moving Pictures Coding Experts Group». MPEG has been started at January, 1988. Since the first assembly in May, 1988, the group began to grow, and has grown up to unusual dense experts collectively. Usually, in MPEG assembly about 350 experts participate, from more than 200 companies. The largest part of participants are the experts occupied in various scientific and academic establishments. Today MPEG group has developed the following standards and algorithms:
- MPEG-1 (November 1992) - the standard of coding, storage and decoding of moving pictures and audio data;
- MPEG-2 (November 1994) - the standard of data coding for digital TV;
- MPEG-4 - the standard for multimedia applications;
- MPEG-7 – universal standard for multimedia, intended for processing, filtration and management of multimedia data.
Let us consider the set of standards MPEG-1. This set, according to ISO standards (International Standards Organization), includes three algorithms of different levels of complexity: Layer 1, Layer 2 and Layer 3. Our well known friend MP3 in exact designation is “MPEG-1 Layer 3”. The general structure of encoding process is identical in all Layers. At the same time, in spite of similarity of the Layers in the general approach to encoding, the Layers differ on target use and internal mechanisms. By the way, this fact determines the degree of similarity of the algorithms which have «grown» from MPEG-1 (such as, Ogg Vorbis and MusePack). Each Layer has its own format of data stream and decoding algorithm. MPEG-1 algorithms are mainly based on known properties of perception of sound signals by a hearing aid of human (we have mentioned above about these techniques).
Briefly about encoding algorithm used in MPEG-1. At the beginning of encoding, the source audio stream with the help of filters is divided on bandwidth. The continuation of the encoding process depends on used Layer.
In the case of Layer 3 (MP3) the signal in each obtained bandwidth is decomposed on frequency components by applying MDCT ( Modified Discrete Cosine Transform – a special case of Fourier Transform) that gives a set of coefficients. Further processing is focused on simplification of the signal in order to perform re-quantization of its spectral coefficients. Obtained spectrum is cleared (by filtering) of obviously inaudible components - low-frequency noise and high imperceptible spectrum components. At the next stage, considerably more complex psycho acoustic analysis is applied (as was described earlier) on the audible part of spectrum. After all these manipulations, the source signal is deprived of more than half of its information. In completion of all, compression of obtained stream by the simplified analogue of Huffman algorithm is performed (this is lossless compression method), that allows to reduce noticeably the stream size.
In the case of Layer 2 the simplification process is quite similar. The difference consists in the object of re-quantization: re-quantization is performed on amplitude signal in each sub-band and not on the spectrum coefficients (some non-MP3 lossy encoders are based on the same technique).
Complete set MPEG-1 is intended for coding signals with sample rates of 32, 44.1 and 48 kHz. Three MPEG-1 Layers that were mentioned above have distinctions in encoding mechanisms and, thus, they provide different compression factors and sounding quality of resulting streams. Layer 1 allows keeping signals in format 44.1 KHz / 16 bits without significant losses of quality at bitrate of 384 Kbps that gives 4 times profit of data size. Layer 2 provides, subjectively, the same quality at 192 - 224 Kbps, when Layer III (MP3) gives the same results at 128-160 Kbps. It is impossible to speak about advantages and disadvantages of one Layer compared to another, because each Layer is developed to achieve its own aim. For example, the advantage of Layer 3 actually consists in allowing of data compression 8-12 times (depending on bitrate) without significant losses of original sound quality. At the same time, speed of a compression provided by this Layer is the lowest (it is necessary to note, that on modern CPU’s this restriction is not appreciable at all). Layer II is potentially capable to provide higher quality of coding on account of «easier» internal signal processing during transformation. However, Layer II does not allow to reach so high compression factors, which may be reached by using Layer III.
Nuances of coding
The technique of audio coding is complex enough and has a set of nuances. All of them cannot be explained within the framework of one article; however all the most important should be considered, as almost every user meets with them when encoding.
Data encoding into MP3 (as well as into WMA and OGG) is performed by blocks: the coded file is divided on so-called frames of a certain equal length and each frame is encoded separately and is stored in a target stream. Thus, the target stream also has frame structure. Each frame can be encoded not on any bitrate, but only on one of those included in the standard table for MPEG1 Layer 3 (Kbps): 32, 40, 48, 56, 64, 80, 96, 112, 128, 160, 192, 224, 256, 320 (coding on intermediate bitrates is not stipulated by the standard, though it is possible). Because each frame is processed individually, it is possible to speak about data compression with constant (CBR) and variable (VBR) bitrate.
CBR (Constant Bitrate) is a way of encoding when all frames are encoded on identical bitrate. In other words, bitrate of the whole encoded stream remains constant all along the stream.
VBR (Variable Bit Rate) is a way of encoding when each separate frame is encoded with its own bitrate, calculated by encoder. The choice of bitrate for each frame is performed by the encoder according to performed psycho acoustic analysis.
There is also one more encoding mode - ABR (Average bitrate). Encoding in this mode (it is true, at least, for MP3 coders) is similar to CBR encoding. However this encoding is performed on variable bitrate keeping the same average. Not going into technical details, we shall note that VBR and ABR encoding is much more flexible and, often, more favorable and qualitative, rather than in CBR mode.
It is important to note, that ABR, VBR and CBR modes are used also in many coders rather than MP3.
We shall consider now existing encoding techniques of stereo data stipulated in MPEG-1 Layer 1, 2, 3 standards. These methods, probably, with some different interpretations, are valid not only in MPEG, but also in other codecs.
- Dual Channel . This mode is intended for encoding of audio information in two channels as absolutely independent. In other words, encoding of audio occurs separately in each channel without tracking dependence of a signal in channels. As is implied from the name, this mode is mainly intended for coding of data with two parallel independent channels (for example, speech in English and German languages), and NOT with two channels carrying stereo information of sounding. In general, this mode is not recommended to be used for coding of stereo signal.
- Stereo. This mode differs from the Dual Stereo mode in reservoir usage. Reservoir - is a mechanism that is responsible for assignment of bits for encoded frames in the target stream. During encoding in stereo mode both channels are processed using the same reservoir, when in Dual Stereo mode, the signal is encoded, using independent reservoir for each channel. There are no other differences between the modes.
- Joint Stereo is common definition of the encoding methods of stereo information, which are based on the use of its redundancy. There are two versions of this method described in MPEG-1.
- MS Stereo . In this mode the encoded signal is re-divided on a middle channel (common constituent for both right and left channels) and a side channel (differented constituent of the channels) and processed as in Stereo mode, using some additional tricks.
- Intensity Stereo. In this mode encoded signal is divided on bandwidths. Then only bottom frequency ranges pass the actual encoding. In the top range, the encoder only registers average signal power in each bandwidth and actually doesn’t encode the signal there. Encoding of stereo information in the bottom ranges is performed using MS Stereo or Stereo modes.
It is necessary to note, that usage of MS Stereo mode does not introduce any additional errors in the signal. When re-dividing <left> + <right> channels on <middle> + <side> channels, nothing occurs, except for harmless and completely convertible mathematical calculations. At the same time, this simple reception of stereo data encoding allows the coder to accomplish its potential more effectively, rather than in mode Stereo.
ОGG - Ogg Vorbis
One of unpleasant features of codec MP3 always was its commercialization: each manufacturer creating the new MP3 encoder is obliged to pay deductions to the «fathers» of the codec. Such situation should have called for appearance of any new development in audio compression. And this has happened indeed.
Codec Ogg Vorbis was published in June 2000. Ogg Vorbis is a part of Ogg Squish project, which consists in developing of completely independent open multimedia system. In other words, the whole project itself, as well as Ogg Vorbis in particular, is open and free for distribution and for its usage as part of a new software. In developers FAQ (Xiphophorus group) it is written, that Ogg Vorbis is based on the same ideas as the well known MPEG-1 Layer II. However OGG uses its own original mathematical algorithms and its own psycho acoustic model that exempts it from necessity to pay any license deductions and to have to make other payments to exterior manufacturers of audio formats. Ogg Vorbis is designed for compression of the data on all possible bitrates without restrictions that is from 8 Kbps up to 512 Kbps, but only in VBR mode. CBR mode wasn’t implemented in Ogg Vorbis. The algorithm enables to store in OGG files (containers) detailed comments about audio material, as well as all standard info (artist/composition name, year and so on). Ogg Vorbis also stipulates an opportunity of coding of audio data with several channels (more than two, theoretically up to 255), an opportunity of editing of files contents, and also so-called «scalable bitrate» - a possibility of changing stream bitrate without necessity of its decoding. Ogg Vorbis also supports streaming playback (audio stream can be played back during its downloading from the Internet) and uses its own universal file format which can store any multimedia data of Ogg Squish system.
WMA - Windows Media Audio
Today Windows Media Audio (in abbreviated form - WMA) is own development of Microsoft Corp. The developing of this codec moves ahead successfully. Initially, WMA was developed by Voxware and had the name “Voxware Audio Codec”, however subsequently the company has deserted its completion, having stopped on v4.0. Nevertheless, the codec was not left to decay, and has been completely redeemed by Microsoft. Programmers have seriously rewritten and advanced this codec, and the company has renamed it in Windows Media Audio. WMA is free-of-charge for users, but it is closed for exterior development.
MPEG-1 Layer 3 has been initially standardized for the allowed bitrate values and other key parameters, and WMA was changing in parallel to its growth and development. There are some versions of WMA codec that are available for today: v1, v2, v7, v8 and v9. Version 7 differs from its predecessors in range of supporting bitrates (up to 192 Kbps versus 164 Kbps for v1 and v2), a little bit worse encoding quality and different data structure of output stream. Version 8 of the codec differs from all previous versions by obviously revised advanced psycho acoustic model. Due to this fact encoding quality has increased significantly. So, at 96 Kbps WMA v8.0 may compete in quality with MP3 128 at encoding of not too much exacting audio materials (like pop music). However, for sure, the quality strongly depends on a concrete composition and the equipment used for listening. Ninth version of WMA is logic continuation of the eighth version. Developers announced significant encoding quality improvement in comparison with WMA v8. Version 9 of the codec contains new technology called “Fast Streaming”. This technology is aimed to reduce buffering time of end user’s client software when WMA-stream is transmitted through the Internet. In addition, WMA 9 represents actually the set of codecs. Besides the lossy-coder, this set includes also a number of specialized codecs, like voice encoding codec and lossless codec.
According to various tests and also to the parameters used for configuring of WMA encoder, its mechanism is quite similar to the mechanism of MPEG-1 Layer 3 - the same frame-by-frame compression with presumably the same signal processing methods.
MPC - MusePack
Codec MusePack (MPC) is one more version of lossy-codecs. Its source name is MPEGplus (MPEG +), but the author of the codec was forced to rename his project in MusePack, because of problems which have appeared as a result of similarity of project’s name to the abbreviation “MPEG”. MusePack wasn’t evolved from MPEG-1 Layer III; the codec has grown from MPEG-1 Layer II (like Ogg Vorbis do). MusePack was created by the enthusiasm of two people: Andre Buschmann and Frank Klemm. The codec is based on MPEG-1 Layer II and therefore it is orientated on coding, mainly, at high bitrates (unlike MP3). At the same time, the codec is completely an independent development. It stipulates coding only in VBR mode. The speed of compression and decompression it provides is higher than the speed of the same operations provided by MPEG-1 Layer 3.
On average, quality of MPC encoding on high bitrates (160 Kbps and higher) is sufficiently (if not to say «considerably») better than the quality provided by MP3. This can be explained by distinctions in encoding mechanisms. During encoding, MP3 divides the signal on sub-bands, then in each sub-band performs decomposition of the signal in a set of cosine coefficients (applying MDCT) with further re-quantization of obtained coefficients by applying psycho acoustics. MPC works similarly to MPEG-1 Layer 2: after splitting the signal on frequency sub-bands, it re-quantizes the amplitude signal in each sub-band (applying psycho acoustics). This difference between MPC and MP3 explains noticeable difference of encoding speed of the codecs.
AAC - MPEG-2/4 AAC (Advanced Audio Coding)
MPEG-2 AAC Standard
MPEG-2 was developed especially for TV broadcasts. In April 1997 this set of standards has received an extension, namely, MPEG-2 AAC (MPEG-2 Advanced Audio Coding). Standard MPEG-2 AAC is a result of efforts shared by a number of companies, such as Sony, NEC, Dolby and Fraunhofer Institute. MPEG-2 AAC is a technological continuation of MPEG-1. Because between publication of MPEG-2 AAC and its standardization enough time have passed, there are several versions (implementations) of this codec: Homeboy AAC, AT*T a2b AAC, Astrid/Quartex AAC, Liquifier AAC, FAAC (Freeware Audio Coder), Mayah AAC and PsyTEL AAC. Liquifier AAC, FAAC and PsyTEL AAC are those codecs, which provide highest sounding quality in comparison to MPEG-1 Layer III. Almost all codecs which were mentioned above are not compatible among themselves.
The main coding reception used in AAC is similar to MP3 and is based on applying of psycho acoustics. At the same time, AAC is furnished with extensions, providing improvement of output sound quality. In particular, another type of transformations is used; noise processing methods were improved, used new filters bank and another output stream storing technique. Besides AAC allows including so-called “watermarks” in encoded stream. “Watermarks” is the information (copyrights, for instance) built in the output stream which can not be deleted, not having destroyed integrity of audio data. This technology (being a part of Multimedia Protection Protocol) allows supervising of audio materials distribution. By the way, the inclusion of this technology in AAC has represented a serious obstacle on the way of its distribution. It is necessary to note also, that the codec is non backward compatible with MPEG-1 Levels 1/2/3.
MPEG-2 AAC provides three various encoding modes (profiles): Main, LC (Low Complexity) and SSR (Scalable Sampling Rate). Time of encoding and also the quality of output stream depends on profile used at encoding. Main profile provides the best sounding quality at the slowest speed of compression. This is because Main profile includes all that is available in AAC mechanisms of sound analysis and processing. LC profile is simplified in comparison with the Main profile that affects sounding quality of output stream, but also increases speed of compression and decompression. SSR profile also represents simplified variant of Main.
Speaking about sound quality provided by the codec, it is possible to tell, that AAC ( Main) stream at 96 Kbps provides sounding which is comparable to MPEG-1 Layer III 128 Kbps. At 128 Kbps AAC distinctly surpasses MPEG-1 Layer III and the same bitrate.
Standard MPEG-4 AAC
MPEG-4 AAC is a part of MPEG-4 standard. MPEG-4 describes ways of object-oriented representation of multimedia data. The standard operates with objects, organizes their hierarchies, classes and other, builds stages and operates their transfer. As a basis of audio compression in MPEG-4, several standards are used: improved MPEG-2 AAC, codec TwinVQ, and also special speech encoders like HVXC (Harmonic Vector eXcitation Coding) and CELP (Code Excited Linear Predictive). In addition MPEG-4 AAC has a set of mechanisms which provide scalability. But as a whole, MPEG-4 AAC is a continuation of MPEG-2 AAC, providing rules and methods of audio coding (http://faac.sourceforge.net/wiki/index.php?page=AAC). MPEG-4 AAC standardizes the following types of objects (the notion «profile» in MPEG-2 AAC was substituted by the notion “object” in MPEG-4 AAC):
MPEG-4 AAC LC (Low Complexity)
MPEG-4 AAC Main
MPEG-4 AAC SSR (Scalable Sampling Rate)
MPEG-4 AAC LTP (Long Term Prediction)
MPEG-4 Version 2
MPEG-4 Version 3 ( включая HE-AAC)
Apparently, first three are borrowed at MPEG-2 AAC, the fourth is an innovation. LTP is based on methods of signal prediction and it is more complex than the others. Version 2 – is the set of standards which extend encoding tools of MPEG-4. Version 3 – is one more extension of the standard. Its main innovation is HE-AAC (High Efficiency AAC) – a new standard (May, 2003) also known as aacPlus.
aacPlus was announced by Coding Tech. at 9 th, Oct 2002. aacPlus is based on SBR technology (Spectral Band Replication). This technology is intended to provide better transition of high frequencies. Audio codecs based on psychoacoustics have one common drawback: sound quality of encoded files start to degrade quickly when the bitrate falls below 112-128 Kbps. SBR is intended to supplement psychoacoustics and to remove the described drawback. When SBR is used, high frequencies of the source signal are not being encoded; only average intensity of high frequencies in several sub-bands is being registered instead. During decoding, the decoder synthesizes (replicates) high frequencies by copying the low frequencies into high diapason and multiplying them by the registered intensity factor in each sub-band.
About quality and practical applicability of codecs MP3, OGG, WMA, MPC and AAC
Despite completely different origin of all considered codecs, their mechanisms are based on the same idea of «simplification» of input signal, with subsequent compression of simplified data. Each codec has its individual innovations and completely independent implementation; however, as these codecs are based on approximately the same idea, their average compression results in identical conditions (evaluated as size/quality ratio) are approximately at the same level.
Codec MP3 was the first codec which used the idea of signal simplification using psycho acoustics. As of today, disregarding contrivance of competitors, MP3 remains one of the most popular audio codecs. Certainly, it is wrong to talk about MP3 in general, as there are its various independent implementations. One of the most successful and continuously developing implementation of MP3 is Lame Encoder (it is developed by a group of independent enthusiasts and the coder is distributed as free-of-charge). Lame has a set of configuration parameters, allowing fine tuning of encoding individually for each encoded material. If you’re going to encode pop-music with subsequent listening on low/average quality audio equipment, then you can obtain enough good sounding at 128 Kbps. At 160 Kbps you may get even better sounding results, not having dramatically reduced compression factor. If you need an “audiophile quality” to store encoded material in audio collection and to listen to it on high-quality equipment, then you may need to use 320 Kbps (and higher). This bitrate choice will provide the highest sounding quality of compressed materials. Thus, each time when it is necessary to compress audio material, user should consider what are the purposes of the compression and only then, depending on the answer, he may choose the bitrate (as well as other parameters). Practice shows, that it is enough to encode at 160-192 Kbps to obtain quite qualitative sounding of pop- and classical music. When encoding electronic or instrumental music, bitrate requirements maybe higher. When encoding only voice material (lectures, for example), then it is enough to use ultra-low bitrates (below 64 Kbps) as in this case not the sound quality is important, but only legibility of speech at playback.
Ogg Vorbis and MusePack, being followers of MPEG-1 Layer II, yield, on average, appreciably better results of coding on high bitrates compared to MP3. This statement is fair for bitrates of 160 Kbps and higher. Usage of Ogg Vorbis and MusePack on low bitrates is not recommended.
Codec WMA, especially versions 8 and 9, yields slightly better results of coding, than MP3. It is necessary to note, that as practice and different tests show, WMA takes special significance at low bitrates. For example, MP3 at 32 Kbps sounds just awful (on such a low bitrate the signal undergoes hard distortions) while WMA sounds quite properly. This means that at low bitrates WMA is preferable to MP3.
Codec MPEG-2/4 AAC is a direct continuation of MP3. Thus in general ACC wins against MP3 on all bitrates. Though, it is necessary to note, that this result varies from one coder to another.
Thus, user’s choice of codec and compression parameters should be guided by expediency reasons, future usage plans and also reasons of digestibility (in particular, MP3 and WMA files are accepted by many of hardware players while OGG, AAC and MPC files aren’t acceptable by most). User doesn’t need to be afraid that original quality of materials will be irrevocably lost after compression - by using high bitrates, it is possible to obtain almost the original sounding quality, as well as great gain in data size.
Now let us consider approximate bitrate ranges, recommended when encoding typical audio materials using MP3, WMA, OGG, AAC and MPC codecs (see table. 1):
Material type |
Sounding requirements |
Recommended bitrates range, Kbps |
||||
MP3 |
WMA |
OGG** |
AAC |
MPC** |
||
Speech (lectures, radio broadcasts etc.), mono |
Speech legibility |
8 - 64 |
near 16 |
45 and lower* |
16 - 64 |
58 and lower* |
Qualitative sounding |
32 - 64 |
near 32 |
45 and lower* |
32 - 64 |
58 and lower* |
|
Non-saturated pop-music, stereo |
Listening «on the move» (during street walk) |
96 - 160 |
64 - 128 |
64 - 128 |
96 - 128 |
96 - 128 |
Qualitative listening using middle and high class audio equipment |
128 - 256 |
96 - 160 |
96 - 160 |
96 - 160 |
96 - 160 |
|
Symphonic music, jazz, stereo |
Listening «on the move» (during street walk) |
128-160 |
96 - 160 |
96 - 160 |
96 - 160 |
96 - 160 |
Qualitative listening using middle class audio equipment |
160 - 256 |
128 - 192 |
128 - 192 |
128 - 192 |
128 - 192 |
|
Qualitative listening using high class audio equipment |
320 |
320 and higher (WMA 9) |
256 |
256 and higher |
256 |
|
Saturated electronic, rock- and pop-music, stereo |
Listening «on the move» (during street walk) |
128 - 192 |
96 - 160 |
96 - 160 |
96 - 160 |
96 – 160 |
Qualitative listening using middle class audio equipment |
192 - 320 |
160 - 320 |
160 - 256 |
160 - 256 |
160 – 256 |
|
Qualitative listening using high class audio equipment |
320 |
320 and higher (WMA 9) |
320 and higher |
320 and higher |
320 and higher |
|
* - encoder program, possibly, doesn’t allow encoding on lower bitrates
** - encoder works only in VBR mode and thus doesn’t allow specifying exact bitrate value
table 1.
V. Available software
Encoders
As it was noted above, there are many MP3 encoders. The most known of them are: Lame Encoder, Blade Encoder, MP3-Producer and XING Encoder. We have said earlier, that Lame Encoder is up until now the most progressive and qualitative encoder among all other existing coders. Blade Encoder was also developed by enthusiasts; however, today its developing is stopped. As to MP3 Producer, once it was almost the standard of audio encoding; however, after intensive development of Lame encoder, its popularity has subsided and as of today, this program is obsolete. XING Encoder was the first encoder which used VBR mode. At the same time XING never was a qualitative encoder. As a whole, only Lame Encoder can be recommended unambiguously. Lame is the console utility (it works from command line); however, several front-ends were made for it. One of the most successful front-ends for Lame Encoder is RazorLame. You can find Lame Encoder and RazorLame in the Internet (try to search on http://www.google.ru, for instance).
There are only two-three OGG encoders available. OGG developers (http://www.vorbis.com) produce console utilities for work with .ogg files (the complete set issued by developers consists of: encoder, decoder and other additional utilities). One of the OGG-coders supplied by GUI is OggDrop (written by John Edwards). It is a very compact utility with convenient adjustment. There are also other «exterior» developments of OGG-coders, for example Ogg Encoder Decoder which is created by MediaTwins s.r.o. ( http://www.mediatwins.com).
MusePack at the moment is developed by only one man. He produces console utility which one can download here: http: // www.personal.uni-jena.de / ~ pfk/MPP/.
WMA encoder exists only as an official package of its developers http://www.microsoft.com/windows/windowsmedia/. It is the utility for audio and video data encoding. It is necessary to note, that WMA encoder should be used accurately, as there is an option when being switched on, it makes the coder to produce files which can be played only at the same computer.
The “story” of AAC encoders is much more complex. As it was told above, there are various AAC encoders and almost all of them were incompatible with each other (this because of a long process of standardization of MPEG-2/4 AAC). Nevertheless, today MPEG-4 AAC is fully standardized and new modern AAC encoders came out: Nero AAC Encoder (http://www.nero.com), QuickTime ( http://www.apple.com), FAAC ( http://audiocoding.com/faac.php). At the moment AAC doesn’t represent mass encoder, but surely AAC will replace MP3 in the nearest future.
Players
There is an ocean of audio players available today. One of the oldest and most popular universal players is WinAMP (by NullSoft, http://www.winamp.com). Today WinAMP plays MP3, WMA, OGG, AAC, MPC (with the help of plug-ins available in the Internet), and also tracker modules, MIDI and video through built-in Windows codecs. It has fully configurable user interface, supports “skins”, supports adjustment of color scale, and has wide visualization features, advanced play-lists system and many-many more.
From the combines like WinAMP, it is necessary to mention also Sonique ( http://sonique.lycos.com) and Apollo ( http://www.apolloplayer.org). One more remarkable combine is Steinberg MyMP3Pro ( http://www.steinberg.de). It is a powerful and versatile program with a great number of very useful features and is having an excellent sound quality. Using myMP3Pro you can: open/play back MP3, Wave, Aiff, WMA, Ogg Vorbis files and audio CD tracks; Record audio and store it in MP3, Wave, Aiff or Ogg Vorbis format; Export audio in MP3, Wave, Aiff, Real Audio and WMA format; Encode and decode audio in MP3 Pro; Create, store and open Playlists in three commonly used formats; Easily create and use a database - called Pool - which allows you to enter additional information for each song; You can then use a flexible search function to display all songs in the Pool for which a certain word or descriptive term can be found in the available categories; Play back and record Internet Radio MP3 streams in real time; Cut and edit MP3 files in an Editor; Apply EQ (i.e. increase or decrease the level of bass, mid or treble frequencies) and improve the sound, using four additional real time effects; Load and apply up to four (myMP3PRO) high quality VST mastering plug-in effects to the songs that you play, save or record onto CD; Create crossfades between all tracks in the Playlist, upon file export or when recording a CD; Create gapless playback or audio file arrangement on the CD; Create a Surround mix from a normal stereo mix; Automatically normalize audio files. This attenuates all audio files that you play back, record onto CD, upload into a portable player or export as a file to the same average playback level; Store EQ and effects settings with the Playlist; Use freedb's online service to receive title names and artist information about the CD currently in your CD-ROM drive; Store your songs on data CDs and/or audio CDs; Create your own CD and CD jewel case Labels in a special CD Label Editor; Store your songs on external MP3 hardware players; Show or Hide individual program sections; Download files from the Internet with the integrated FTP Browser; Switch between different user interface skins that give your program a different look; Simultaneously play back audio and trigger music-controlled visual effects on your screen.
From among super-compact universal audio players, FooBar2000 ( http://foobar2000.hydrogenaudio.org) is the most noticeable player. This is a very small audio player with almost primitive GUI, but it is very powerful and useful for everybody who do not need these «very friendly» and hard GUI's. Supported formats: MP3, Ogg Vorbis, MPC, FLAC, Ogg FLAC, WAV, MOD, SPC, Monkey's Audio and many others; 32bit floating point audio processing pipeline, with 6dB hard limiter and conversion to 16/24bit (dithered) at the end; lossy formats (MP3, Vorbis, MPC) are decoded directly to 32bit FP so there's no clipping; transparent RAR/ZIP reading; full Unicode support, Playlist format (m3u8) storing international filenames properly (using UTF-8); built in SSRC resampler component (DSP); reads APEv2 tags from MP3 files; fully customizable keyboard shortcuts, including global hotkeys.
Audio CD rippers
Audio CD ripper is a program which performs copying of audio CD contents on HDD (for example, for the subsequent MP3 compression). In spite of the fact that audio CD is the digital storage, quality of data copied from it depends on quality of the disk, CD-drive and software used for copying. In case of “unsuccessful” combination of these factors, copied data may contain errors and noises.
From the most known ripper software it is necessary to note the following programs: Exact Audio Copy ( http://www.exactaudiocopy.de), CDex ( http://www.cdex.n3.net), WinDAC and AudioGrabber. By some independent tests, EAC provides the most qualitative copying. Qualitative copying is achieved due to deep integration and adaptation of copying mechanism and reading CD-drive.
VI. To compress or not to compress? - that is the question:
« So, to compress or not? » - that question might be asked after reading all this long material about lossy-coding. The answer to this question is strictly individual and everyone should answer it independently. Whether to use lossy-coders for audio compression, whether to use digital equipment or to stay with analog equipment - among music fans these disputes didn't cease till now and, probably, will never be resolved. One can say that analog record keeps «vivacity» of a sound which is destroyed by analog-digital conversion; others, on the other hand, assert that the best sounding quality can be achieved only with the use of the digital equipment. Someone keeps the data in audio collection in an original digital form on audio CDs, thinking about lossy-coding as if it was a blasphemy; on the other hand, someone else encodes all his files into MP3 (or WMA/AAC/…).
The writer of this article also finds it difficult to reach strict decisions concerning these questions; however, obvious advantages of compressed digital audio should be mentioned here. These advantages are compactness and longevity.
The longevity (with regard to digital audio data in general) consists that at the safe digital storage, the data stored on it is not deformed eventually. If magnetic tape with time becomes demagnetized and looses quality, if vinyl disk is scratched and its sound becomes noisy (with clicks and pops), - the HDD, flash memory or any other type of electronic digital storage don’t have all these disadvantages: they are neither readable or doesn’t readable at all.
Compactness is, first of all, small dimensions of modern storage devices. General distribution and further development of lossy audio compression technologies (MP3, OGG, WMA, MPC, AAC and others) opens broadest opportunities of audio distribution and storage. Not long ago an average audio collection was occupying several shelves or even the whole room; today even ten times bigger audio collection may be placed in a pocket player. Furthermore, thanks to audio compression techniques, the Internet allows everyone to get quality music without leaving his computer; not to mention the opportunity to talk by cellular phone, where the voice is transferred using special encoding techniques. In other words, the appearance of audio compression methods changed audio data transfer into daily routine, remitting all barriers concerned with slow communication links.
As for the quality of compressed audio materials (in lossy format), as could be understood from the article (or simply to be convinced by practice), it all depends on competence of the use of coders and on general approach to compression. With a correct choice of the coder and encoding parameters, it is always possible to achieve the necessary audio quality. As it was mentioned above, to make a correct choice, it is necessary to think about the purpose of the compression (for example, archival compression or compression for subsequent listening in a portable player), to decide what equipment will be used for listening, and also to consider other factors which can affect the choice of the codec and encoding parameters. The fact, that compressed into lossy-format audio, degrades in quality, in comparison to the quality of original digital data, is indisputable; however it is also indisputable, that the level of these losses is completely depends on the user. Competent usage of lossy-encoding is capable to satisfy the most fussy and fastidious.
The conclusion
The considered technologies of lossy audio compression, apparent from the article, can be the most powerful tool in the hands of the skilful user. MP3, OGG, AAC, MPC and WMA are the convenient and effective algorithms of audio compression, they are widely distributed and most of them are internally supported by growing amount of electronic audio equipment. The purpose of this article was to dispel the prejudiced attitude to lossy audio coders, and also to force music fans and regular computer users to look with renewed outlook at audio compression. The task of this article also was to help the beginners (and also the experienced users) to understand opportunities and nuances of these technologies. The writer hopes that all these goals are achieved.